Functional Annotation with PfamScan
Introduction
Pfam is a database of protein families. Each entry combines a seed alignment and a profile hidden Markov model (HMM) built with HMMER. Matches above a curated threshold are aligned back to the profile. Functional notes from the literature are added where available. The sequence database pfamseq is built from UniProt Reference Proteomes for scalability.
Open the wizard from Metagenomics → Annotation Tools → PfamScan.
For orthology-based GO and COG annotation, see Functional Annotation with EggNOG Mapper.
Input
- Genes or Proteins: One or more multi-FASTA files containing gene or protein sequences.
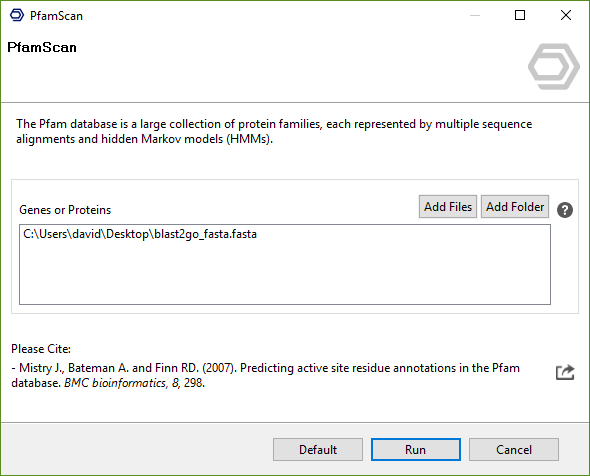
Figure 1. PfamScan wizard.
Results
The result table summarizes PfamScan hits. Use sorting, filtering, and the context menu to inspect entries (Figure 2).
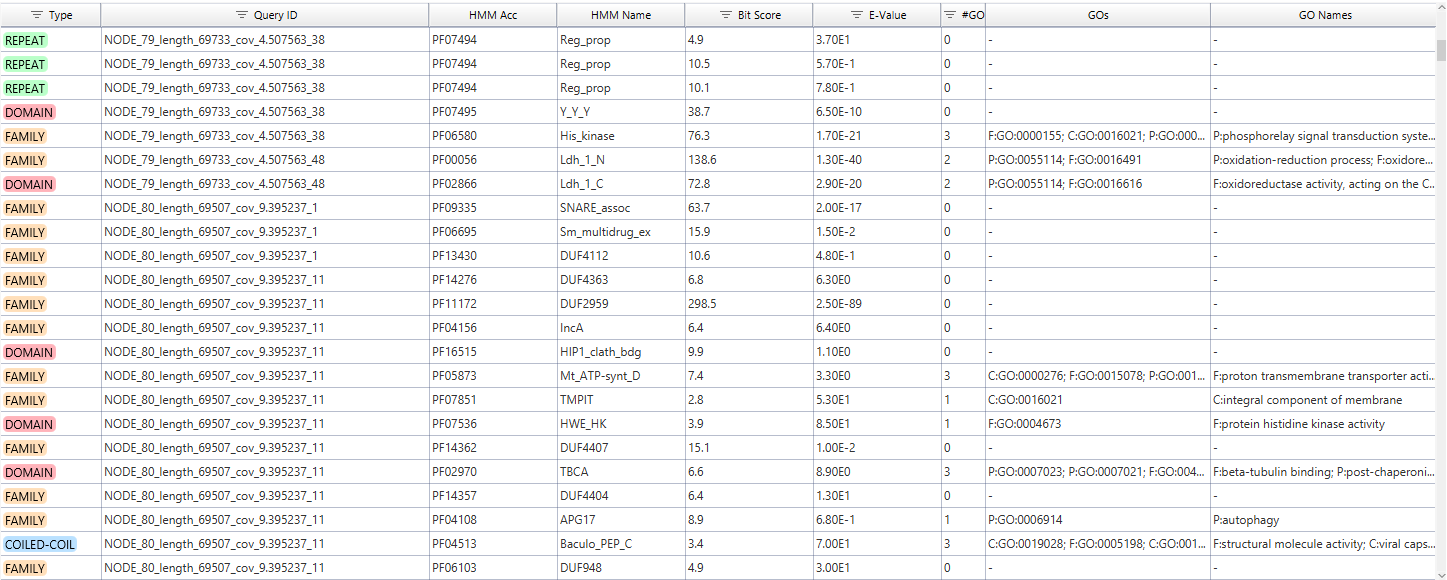
Figure 2. PfamScan results table.
Right-click a sequence and choose Show Annotation Details for link-outs and domain or family details (Figure 3).
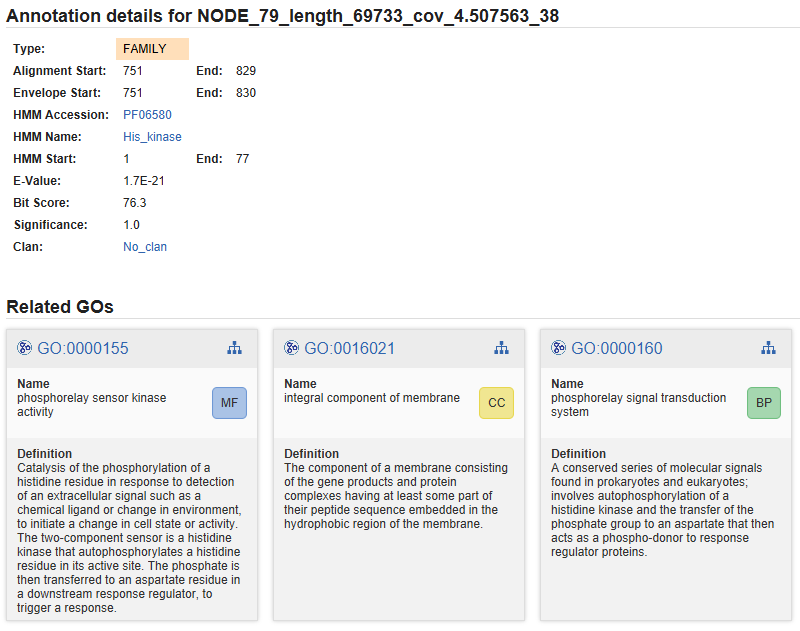
Figure 3. PfamScan annotation details.
References
El-Gebali S et al. (2019). The Pfam protein families database in 2019. Nucleic Acids Research, 47(D1), D427-D432. doi: 10.1093/nar/gky995